프로젝트에서 진행했던 쿼리 최적화들을 기록해본다.
1. join fetch 활용
- ex) 게시물 상세 조회 쿼리를 3번 → 2번으로 줄임
//변경 전
User user = userRepository.findById(userId).orElseThrow(UserNotFoundException::new);
Board board = allBoardRepository.findBoard(boardId).orElseThrow(BoardNotFoundException::new);
boardLikeRepository.save(BoardLike.builder().user(board.getUser()).board(board).build()).getId();
//변경 후
Board board = allBoardRepository.findBoard(boardId).orElseThrow(BoardNotFoundException::new);
boardLikeRepository.save(BoardLike.builder().user(board.getUser()).board(board).build()).getId();findBoard가 fetch join으로 user까지 이미 끌고 오기 때문에, userRepository.findById 부분은 불필요해서 제외함.
2. entity graph 활용
: jpql을 활용한 paging 시 페치 조인을 사용할 수 없기에 entity graph를 사용함
3. 중복 결과 데이터를 최소한으로 줄임
‘내가 쓴 댓글’ 리스트를 보내줘야 했는데, 댓글 리스트를 반환하면 그에 속해있는 다른 자식 domain도 같이 반환되어서 낭비 및 중복되는 데이터가 많음을 발견했다.
예를 들어 필요한 건 '댓글 내용' 밖에 없는데 BoardComment의 경우 user와 Board 데이터가 같이 오고, StudyComment의 경우 user와 study 데이터가 같이 오는 것이다.
또한, 동일한 게시물에 여러 개의 댓글을 달 경우 그만큼 또 같은 데이터가 중복되어서 조회되게 된다.
그래서, 프론트 팀원들과 협의 후 ‘내가 댓글 단 글’로 탭 이름을 변환하고, 유저가 댓글 단 글의 목록을 distinct로 뿌려주게끔 하여서 중복 및 낭비 데이터를 줄였다.
4. delete query 최적화
SpringDataJpa에서 deleteByXXX 등의 기본 메서드를 사용했더니, delete 쿼리에서 n+1 문제가 발생했다.
예를 들어 company의 경우 각 데이터 당 delete쿼리가 '채용공고의 각 scrap갯수 + 채용공고 갯수 + 회사 댓글 갯수'만큼 나가는 것이다.
이 문제가 발생한 이유는, jpql에서 제공하는 기본 delete 메서드는 여러건을 삭제하더라도 "먼저 조회를 하고 그 결과로 얻은 엔티티 데이터를 1건씩 삭제하기 때문"이었다.
그리고 보통 연관관계에 습관적으로 넣는 cascade옵션도 하위 엔티티들을 마찬가지로 한 건씩 삭제하기 때문에 동일하게 N+1 문제가 발생하였다.
이를 해결하기 위해 범위 조건의 삭제 쿼리를 직접 생성하고, 삭제 쿼리도 자식 먼저 삭제 후 부모 엔티티를 삭제하게끔 수동으로 날려서 N+1 쿼리를 2~3번으로 줄였다.
즉 각 하위 엔티티 그룹 당 delete 쿼리가 하나만 나가게끔 해, 각 하위 엔티티가 한방으로 삭제되게 하였다.
예를 들어 Board와 BoardComment를 보면
@Transactional
@Modifying
@Query("delete from BoardComment c where c.board.id = :boardId")
void deleteByBoardId(@Param("boardId") Long boardId);BoardComment를 삭제하는 쿼리를 직접 재정의하여 만들었다.
또, Board를 삭제하는 서비스단에서는
@Transactional
public Long deleteBoard(Long userId, Long boardId) {
Board board = boardRepository.findById(boardId).orElseThrow(BoardNotFoundException::new);
validBoardUser(userId, board.getUser().getId());
boardLikeRepository.deleteByBoardId(boardId);
boardCommentRepository.deleteByBoardId(boardId);
boardRepository.deleteById(boardId);
return boardId;
}이렇게 자식 먼저 삭제 후 부모 엔티티를 삭제하게끔 하였다.
이 해결방법은 이 사이트를 참고해서 진행한 것이다 : https://jojoldu.tistory.com/235
이 방법으로 모든 도메인의 delete를 변경하던 도중, company domain에서 문제가 하나 생겼다.
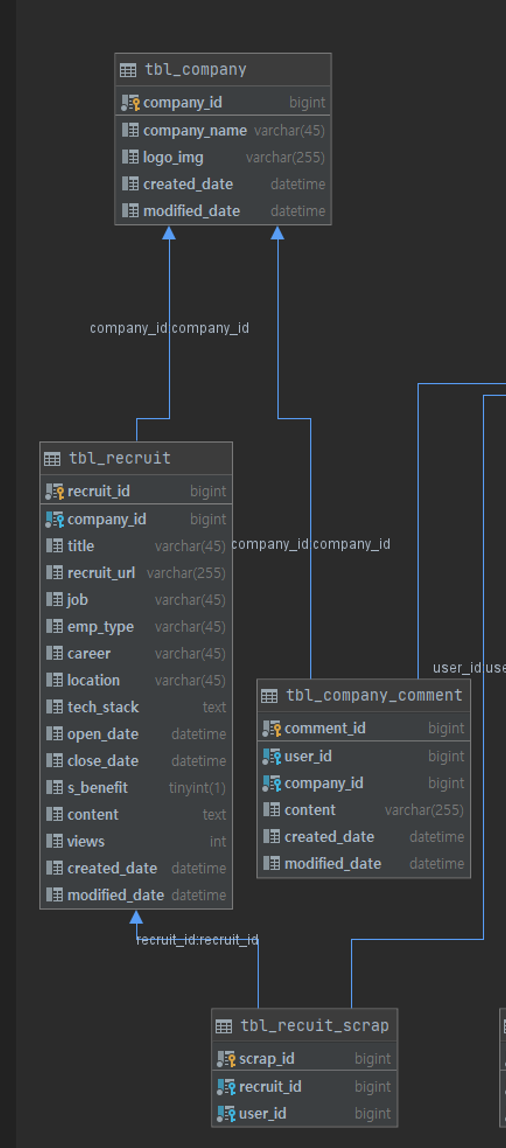
위 ERD를 보면 company를 삭제하는 부분에서 연관관계를 두 번 거슬러 올라가 Recruitscrap까지 삭제해야 함을 확인할 수 있다.
하지만 RecruitScrapRepository에서 두 번 거슬러 올라가 companyId를 조회할 수가 없어서, 그냥 recruit을 삭제하는 데 있어 jpql의 기본 메서드(deleteByCompanyId)와 cascade, orphanRemoval 속성을 통해 scrap까지 삭제시키는 방법을 택했다.
때문에 company 삭제 시, 쿼리는 '채용 공고의 각 scrap 갯수 + 채용 공고 갯수 + 2개(회사 댓글 삭제, 회사 삭제)'개가 나가게 된다.
하지만 company 삭제 같은 경우는 회사가 파산하지 않는 이상 잘 일어나지 않을 호출이라 생각되어 이렇게 고치는 것도 그렇게 나쁠 것 같진 않다.
그리고 지금 와서 생각해보니 애초에 db 설계할 때 recruit_scrap table에 company_id column을 추가했다면 쉽게 해결됐을 문제였다.
이를 교훈 삼아 다음 프젝 때는 이런 것도 고려해서 db를 설계하면 좋을 것 같다는 생각이 든다.
5. hibernate.default_batch_fetch_size 활용
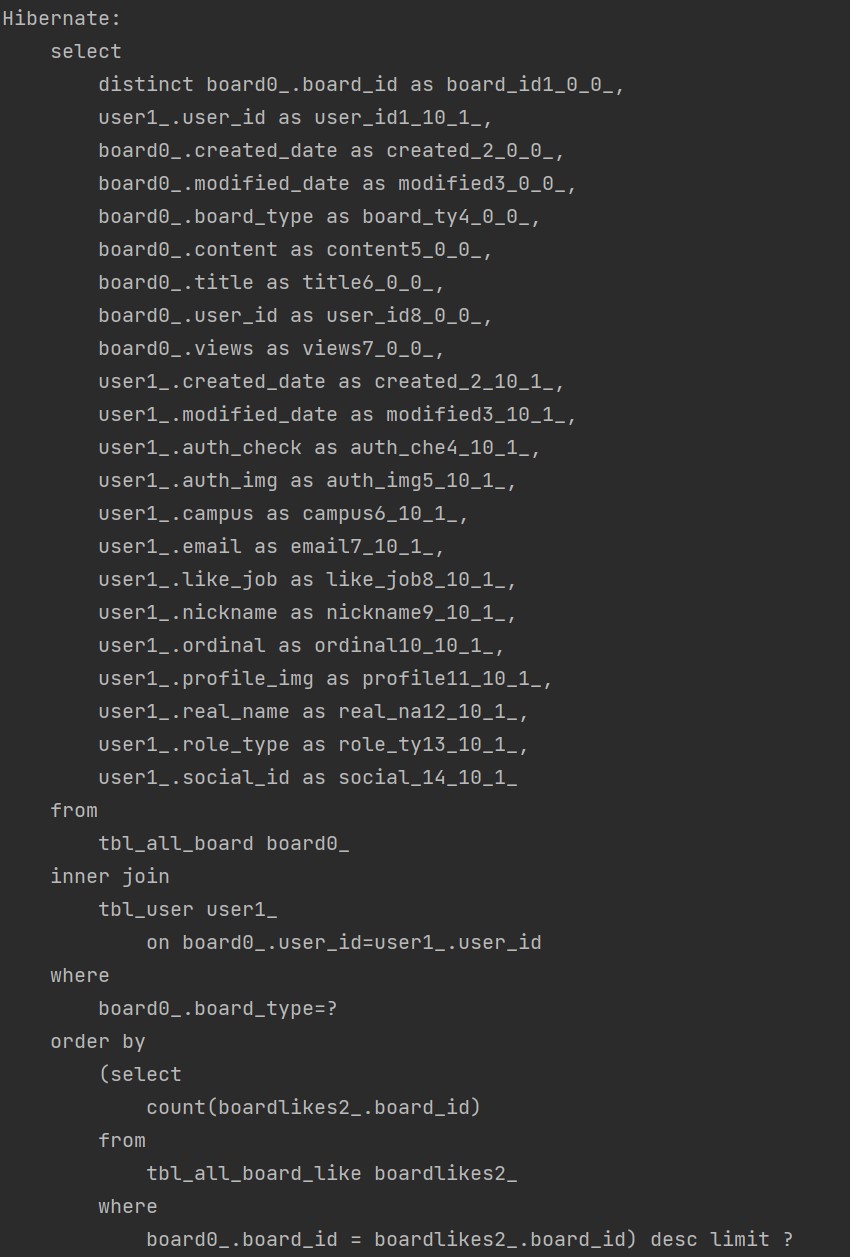
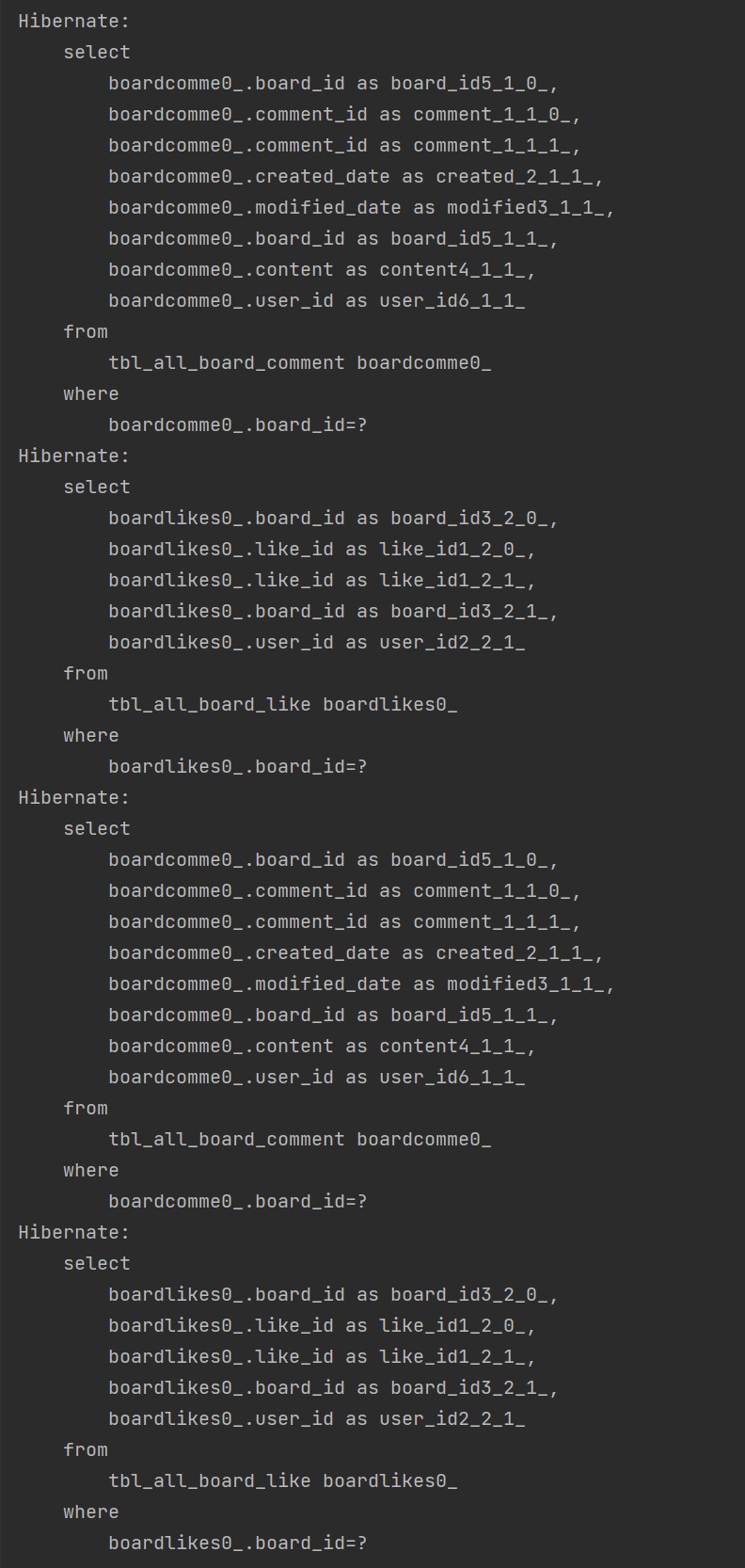
게시판 전체 조회 시, 해당 게시물에 대한 전체 댓글 갯수와 전체 좋아요 갯수를 띄워줘야 하는데 그 과정에서 2*N+1개의 쿼리가 발생되었다. (게시물 조회(1개) + 게시물에 달린 댓글 갯수(N개) + 게시물에 달린 좋아요 갯수(N개) 만큼의 쿼리가 발생했다)
온갖 방법을 시도해 봤는데도 이 문제는 해결되지 않았고, 페이징이 걸려있는데다가 애초에 comment와 like는 Board와 OneToMany 관계라 페치 조인도 불가능했다. (Entity Graph의 경우 둘 중 하나만 가능했는데, 콘솔에서 HHH000104 워닝 떠서 어차피 버려야 하는 방법이었다..^^)
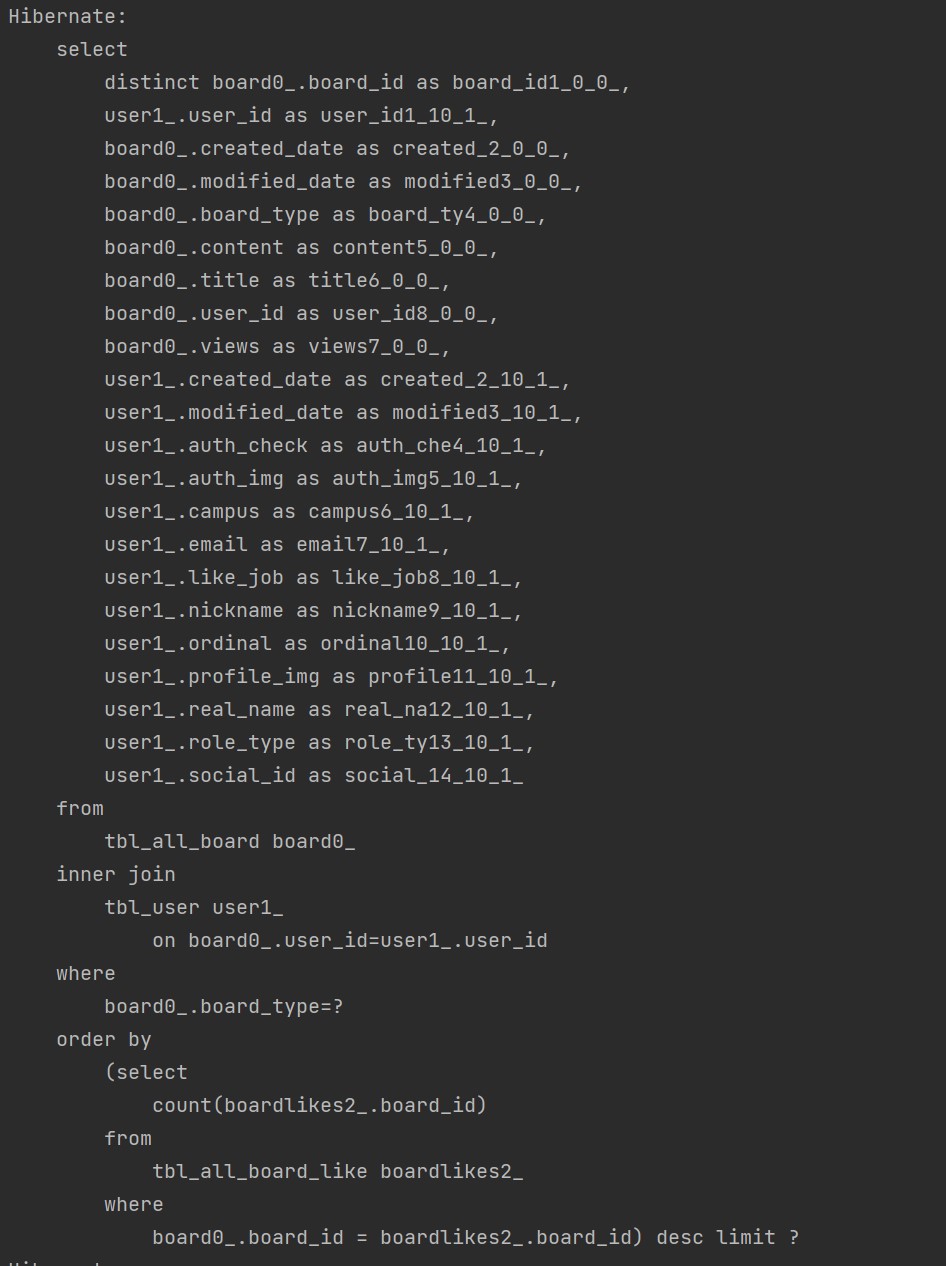
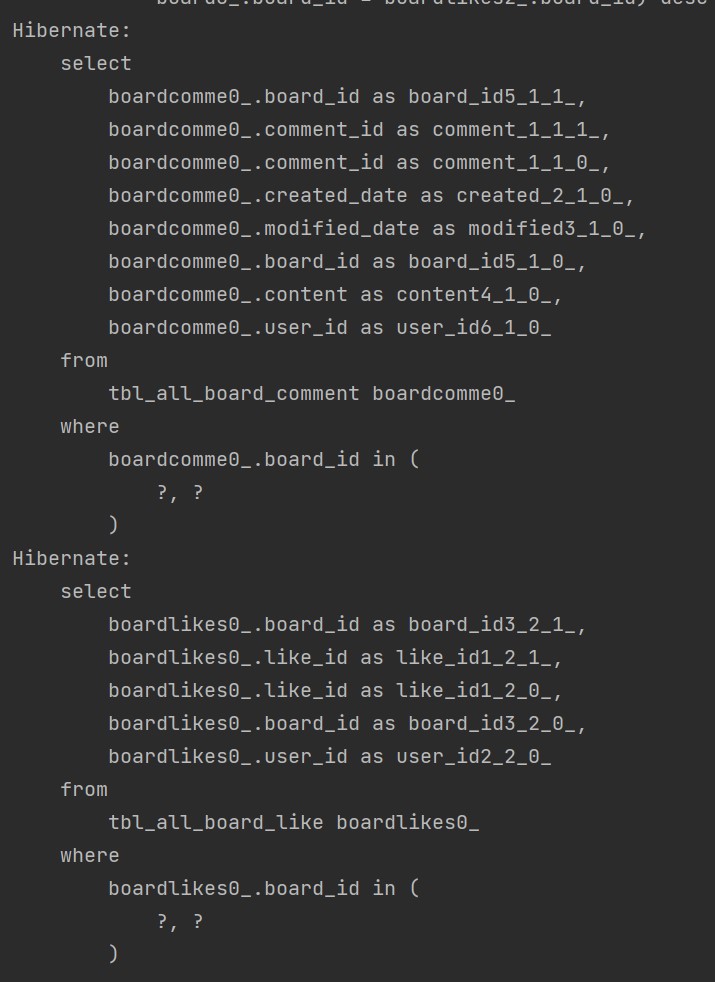
결국 거의 포기하려던 참에 default_batch_fetch_size 방법을 알게 되어서 글로벌하게 적용시켰더니, 3번으로 쿼리가 줄어들었다!! 그래서 그때 너무 기뻐서 혼자 소리질렀었다..ㅎ
왜 이렇게 간단한 방법을 늦게서야 알았는지..그래도 해결되어서 다행이었다.
최적화 전(댓글 2개, 좋아요 2개) :
최적화 후 (댓글 2개, 좋아요 2개) :
'프로젝트 기록' 카테고리의 다른 글
| 코드 리팩토링 기록 - JPA Embedded 타입 활용 (0) | 2022.02.24 |
|---|---|
| JMeter 성능 테스트 기록 (0) | 2022.02.23 |
| MySql 시간 설정 삽질 기록 + 기타 기록 (0) | 2022.02.23 |
| SpringBoot Dockerize 기록 (0) | 2022.02.23 |
| MobaXterm을 통한 배포 기록 (0) | 2022.02.23 |



